
The Progress of EdTech Depends on Our Tolerance for Error
Tolerate tiny mistakes where they’re safe; architect systems so they never scale

I was scrolling through the usual sycophantic LinkedIn posts about how wonderful corporate life is when a post from my science teacher friend Adam Robbins caught my eye. It was a photo of a GCSE chemistry prompt on Sparx’s science platform with Adam’s caption: the question is wrong, and not even on the spec. He suspected an LLM rather than human was to blame; either way, his trust in the platform had nosedived.
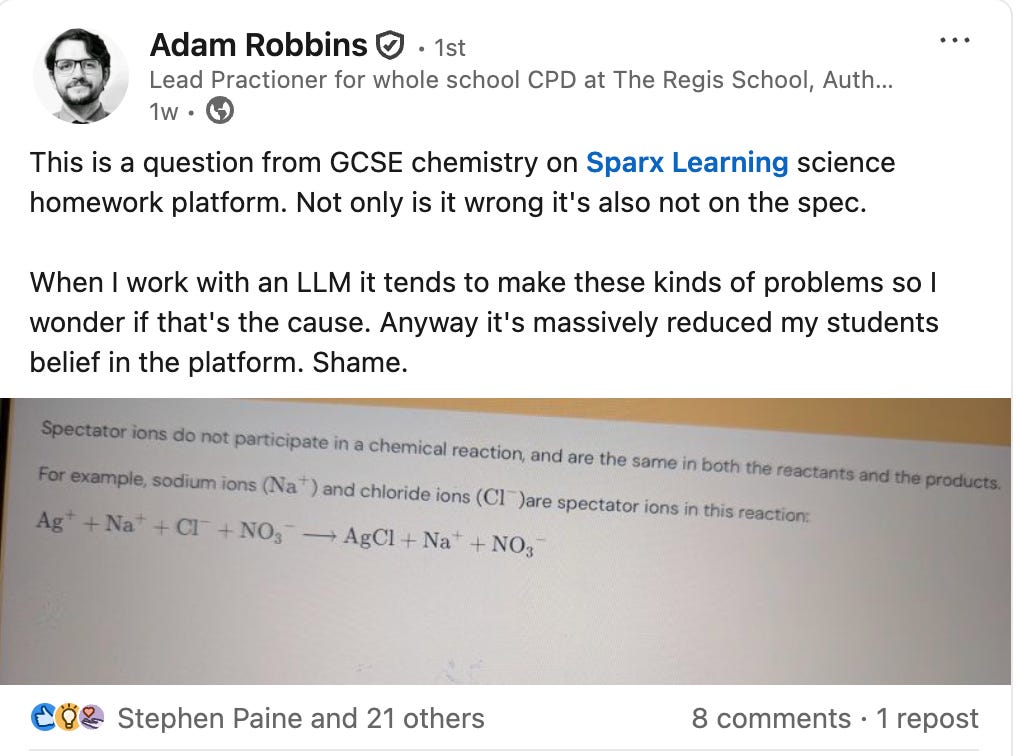
This isn’t the drama of a national exam error… …we’ll come to those later. But these everyday nicks in the surface of credibility are what bleed confidence in EdTech platforms. I don’t know whether an LLM actually wrote that question, but whether human or machine, the problem was that the one error was likely multiplied by the platform’s scale across many classrooms.
This is the pinch point for EdTech right now. We want AI-powered tools in the inner loop, giving students rapid feedback and teachers useful signals. We’d love the dialogue, chat-based support LLMs seem to promise, though it never quite appears. But the moment an error pops up in front of real pupils, our tolerance collapses; we expect zero wrongness from software in a way we don’t from textbooks, exam papers, or (let’s be honest) ourselves.
Seeing Adam’s post, I found myself asking a harder question than “Was this AI?” I asked: what kind of ecosystem would make that error survivable? Flagged quickly, capped in exposure, fixed before it propagates further. That is the ecosystem I want to talk about in this post.
Self-driving cars and the “march of nines”
On a recent episode of the Dwarkesh Podcast, Andrej Karpathy described his time at Tesla with a phrase that sticks: “the march of nines.” You get something working ~90% of the time—the first nine—and everyone cheers. You’re nearly there. Then you push to 99%. Harder. Then 99.9%. Brutal. Each extra nine demands another mountain of engineering because the remaining failures are weird, rare, and safety-critical.
Using LLMs in EdTech feels the same. With careful prompts, they already achieve the first nine of marking or explanation: they are helpful about 90% of the time. That’s why the demos wow us. But climbing from 90% to 99% is painful as the edge cases pile up, and 99.9% looks brutal. Children only get one shot at schooling, so we demand reliability; we keep asking for more nines until, in truth, we’re asking for zero.
Exponential progress dazzles at first—big, obvious wins—then turns invisible as we chase the last nines. Luckily, an EdTech error isn’t a self-driving crash. Still, we’ll be waiting forever to build “certifiable, sellable, zero-fault” systems that flex efficiently with the messiness of individual learning. So we must design for the march: celebrate the nines we’ve won, and build guardrails so the remaining nines don’t do much damage.
Right now we hold AI to a zero-error bar where humans routinely slip, and that stalls the inner-loop feedback we want. Why tolerate teacher errors but not LLM errors? Exposure. A teacher’s mistake hits one class. A platform’s mistake can hit thousands, unless we architect systems that sharply limit exposure as errors occur.
Architecting to detect and limit errors
If we let LLMs play a role in learning platforms, mistakes will creep in, not least because we ideally want them to flexibly interpret as yet unseen situations. They tend to show up in two places: instruction (a shaky explanation) and assessment (a dodgy item or marking judgement). Assessment is the easier one to police, so start there.
When you can’t pre-vet every new prompt-response pair with experts, you can still validate safely in the wild. Mix a small number of new items among well-understood ones so you already know roughly how capable each student is in that topic. As answers come in, the system keeps a running estimate of whether the new item behaves like it should: do stronger students get it right more often than weaker ones? Is the pass rate roughly where you predicted? If not, you cap exposure (only dozens see it, not thousands), pull the item for review, and fix or replace it. Think of it as smoke detectors for questions: a few odd readings and the alarm goes off before anyone gets hurt.
Instruction is harder because a new explanation and new questions can fail together and it’s not obvious which one is at fault. The workaround is to keep some trusted “anchor” questions in the mix, or to A/B a new explanation against your current best one. After a lesson, do the students you’d expect to succeed actually succeed, and do they do so faster than the ones who usually struggle? You can also watch early warning signals—unusual time-on-task, spikes in help requests, lots of retries—which often tell you an explanation missed the mark even before the scores settle. These signals mirror the informal feedback teachers rely on when they sense an explanation hasn’t landed and look to their most confident student for confirmation.
Under the hood, you want a system that updates continuously as each new response arrives (a light Bayesian mindset rather than a once-a-year audit), with simple rules for when to pause, repair, or retire an item or explanation.1
This approach should be simple enough for teachers to trust and robust enough for platforms: we can’t promise there will never be a bad question or a wobbly explanation, but we can limit how many learners ever see it, catch it quickly, and learn from it.
What about higher-stakes situations?
Since it’s the season for curriculum and assessment reviews in England, let’s briefly return to errors in public examinations. They’re what keep exam-board heads awake in early summer, and they’re impossible to eliminate entirely, even in heavily audited systems. Human systems are subject to the march of nines too.
No, I’m not suggesting we start throwing unseen LLM-generated questions into the high-stakes summer GCSEs. We can’t, for two reasons: (1) the consequences for the student, and (2) the sheer number of students who would encounter any error that slipped through.
But the existing on-demand Functional Skills qualifications (yes, the ones squarely under the spotlight in this week’s white paper) hint at how other public assessments could work. Imagine walking into a test centre and sitting an assessment unique to you.
To do that, you need a question bank large enough that memorisation is futile, i.e. you have to understand the subject matter to pass. That’s exactly where LLMs excel: generating vast, varied item pools across subjects. The obvious worry is validation and calibration: what if we’re only 99.9% sure an item is suitable, and we don’t yet know its difficulty or discrimination (which we need to set fair pass marks)? The fix is simple and contained: the test taker helps validate. Ask, say, 30 questions; score 25; use 5 seed items to collect data quietly. Better still, awarding bodies run a companion tutorial app where candidates practise and get a readiness score; the response data pre-calibrates items long before they reach high-stakes use, shrinking the need for seeds.
How does this help? Errors still happen, but they surface in low-stakes settings and in tiny numbers, not broadcast to thousands on a single day in May. That’s how you protect trust while still making room for more flexible and efficient qualification systems.
Tolerate tiny mistakes, prevent mass errors
Back to Sparx. Could Adam’s class have been spared that bungled item? Probably. Odds are he wasn’t the first—or even the 20th—to see it. With a live back-end tracking each item’s behaviour, low-discrimination or off-spec questions should trip an alarm fast and get paused, fixed, or binned. That’s how you avoid broadcasting errors.
Is this better than purely expert-curated content? Yes, actually. Humans write bad questions too; we just tend to forgive them. The difference here is speed and scale: a modern system can surface, cap, and correct faults far quicker than any textbook ever could, while giving students the ocean of varied practice I never had as a student.
If we insist on “error-free everywhere,” we’re demanding a standard we don’t apply to teachers and guaranteeing we ship nothing new. The way forward is to design for the march of nines: tolerate tiny, contained mistakes; instrument everything; cap exposure; fix fast. That’s how we protect trust and finally deliver the inner-loop feedback tools we’ve been promised.
Note - both these approaches depend on multiple students receiving the same question, feedback, explanation etc… Detecting errors in personalised chat situations is a little more tricky.
Thanks for this - I enjoyed reading. My feeling is that until a an LLM can continuously update, a sort of data flywheel I think it's been referred as, then user trust will be compromised. Systems need agility to improve just as you would expect a teacher to correct a mistake (and I've made a few mistakes in my time) Teachers/users also need to know this is the case & have evidence of that continuous updating. I think it also highlights teachers aren't just the sage on the stage.
Sorry if this is just repeating what you've already said :)
Thanks again for a great post.
Love this perspectiv, you've really hit the nail on the head about our unrealistic zero-tolerance for EdTech errors compared to how we treat human mistakes. As someone who teaches both math and CS, I see this tension daily; it's almost like we expect a perfect, bug-free initial commit every time without any thought for the version control or rapid patch deployment needed in real world software.